《汇编语言》- 读书笔记 - 综合研究
- 研究试验 1 搭建一个精简的 C 语言开发环境
- 1. 下载
- 2. 配置
- 3. 编译
- 4. 连接
- 研究试验 2 使用寄存器
- 1. 编一个程序 ur1.c ( tcc 用法)
- tcc 编译连接多个源文件
- tlink 手动连接
- 2.用 Debug 加载 ur1.exe,用u命令査看 ur1.c 编译后的机器码和汇编代码
- 3. 用下面的方法打印出 ur1.exe 被加载运行时,main 函数在代码段中的偏移地址:
- 4. 用 Debug 加载 ur1.exe,根据上面打印出的 main 函数的偏移地址,用 u 命令察看 main 函数的汇编代码。仔细找到 ur1.c 中每条 c 语句对应的汇编代码。
- 5. 通过 main 函数后面有 ret 指令,我们可以设想:C 语言将函数实现为汇编语言中的子程序。研究下面程序的汇编代码,验证我们的设想。
- 研究试验 3 使用内存空间
- 1. 编一个程序 um1.c
- 2. 编一个程序,用一条C语句实现在屏幕的中间显示一个绿色的字符 a
- 3. 分析下面程序中所有函数的汇编代码,思考相关的问题
- 1. C语言将全局变量存放在哪里?
- 2. 将局部变量存放在哪里?
- 3. 每个函数开头的 `push bp mov bp sp` 有何含义?
- 栈帧(Stack Frame)
- 4. 分析下面程序的汇编代码,思考相关的问题。
- 5. 下面的程序向安全的内存空间写入从“a”到“h”的 8 个字符,理解程序的含义,深入理解相关的知识。(注意:请自己学习、研究 malloc 函数的用法)
- 研究试验 4 不用 main 函数编程
- 1. 编译,连接这段代码思考相关问题
- 1. 编译和连接哪个环节会出问题?
- 2. 显示出的错误信息是什么?
- 3. 这个错误信息可能与哪个文件相关?
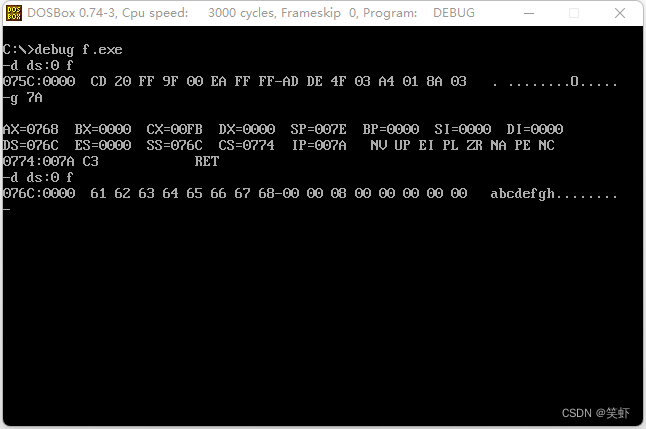
- 2.用学习汇编语言时使用的 link.exe 对 tc.exe 生成的 f.obj 文件进行连接,生成f.exe。用 Debug 加载 f.exe,察看整个程序的汇编代码。思考相关的问题。
- 1. f.exe 的程序代码总共有多少字节?
- 2. f.exe 的程序能正确返回吗?
- 3. f 函数的偏移地址是多少?
- 3. 写一个程序 m.c
- 1. `m.exe` 的程序代码总共有多少字节?
- 2. `m.exe` 能正确返回吗?
- 3. `m.exe` 程序中的 `main` 函数和 `f.exe` 中的`f`函数的汇编代码有何不同?
- 4. 用 Debug 对 m.exe 进行跟踪:
- 5. 思考如下几个问题
- 1. 对 `main` 函数调用的指令和程序返回的指令是哪里来的?
- 2. 没有 `main` 函数时,出现的错误信息里有和 `c0s` 相关的信息;而前面在搭建开发环境时,没有 `c0s.obj` 文件 `tc.exe` 就无法对程序进行连接。是不是 `tc.exe` 把 `c0s.obj` 和用户程序的 `.obj` 文件一起进行连接生成 `.exe` 文件?
- 3. 对用户程序的 `main` 函数进行调用的指令和程序返回的指令是否就来自 `c0s.obj` 文件?
- 4. 我们如何看到 c0s.obj 文件中的程序代码呢?
- 5. `c0s.obj` 文件里有我们设想的代码吗?
- 6. 用 link.exe 对 c:\minic(我的在 c:\TC20\LIB) 目录下的 c0s.obj 进行连接,生成 c0s.exe。
- 7. 用 Debug 找到 m.exe 中调用 main 函数的 call 指令的偏移地址,从这个偏移地址开始向后察看 10 条指令;然后用 Debug加载 c0s.exe,从相同的偏移地址开始向后察看 10条指令。对两处的指令进行对比。
- 8. `tc.exe`(Turbo C 编译器)编译器连接器将 `c0s.obj` 和用户编写的 `.obj` 文件链接生成 `.exe` 文件的过程及其内部运行机制,大致如下:
- 9. 用 tc.exe 将 f.c 重新进行编译,连接,生成 f.exe。
- 10. 在新的 c0s.obj 的基础上,写一个新的 f.c,向安全的内存空间写入从“a”到“h”的8个字符。分析、理解 f.c。
- 研究试验 5 函数如何接收不定数量的参数
- 1.分析程序 a.c
- 2. 分析程序 b.c
- 3. 实现一个简单的 `printf` 函数,只需要支持 `%c`、`%d` 即可。
- myprintf.asm
- main.c
- 测试 %c
- 测试 %d 未指定宽度
- 测试 %d 指定宽度
- 测试 %d 单独用【参数】指定宽度
- 总结
- 反汇编分析 C
- 参考资料
研究试验 1 搭建一个精简的 C 语言开发环境
不差钱,我不要精简的。直接下个绿色版本,能跑起来就行。
1. 下载
Turbo C 2.0 dosbox绿色版 支持win7 64位
喜欢安装版本的可以参考:Turbo C 2.0安装及其使用指南
2. 配置
我的工作目录在E:\c,TC20文件夹直接复制过去。
我用了我原有的 DOSBox 快捷方式目标:E:\DOSBox\DOSBox.exe -conf "dosbox-for_TC20.conf" -noconsole
[autoexec]
# Lines in this section will be run at startup.
# You can put your MOUNT lines here.
mount c E:\c
set PATH=%PATH%;c:\TC20;
c:
# 挂载软盘镜像为 A 盘
imgmount A E:\c\A.flp -t floppy -fs fat -size 1440
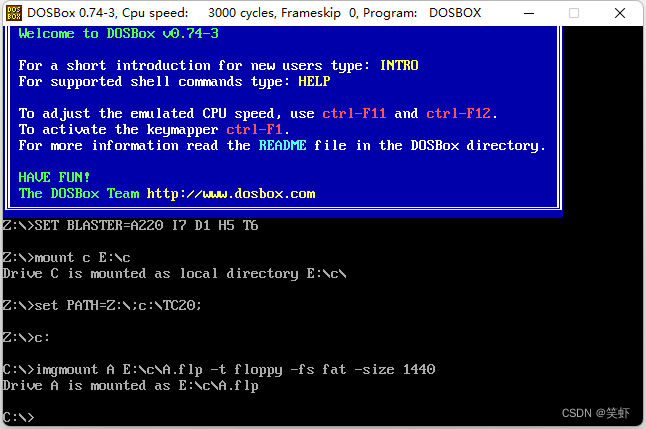
如果 TC20文件夹改了名,使用时找不到东西会报错,这里要自己改一下。

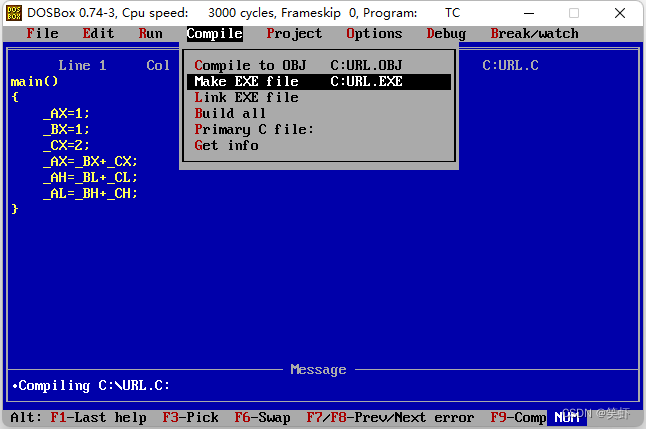
3. 编译
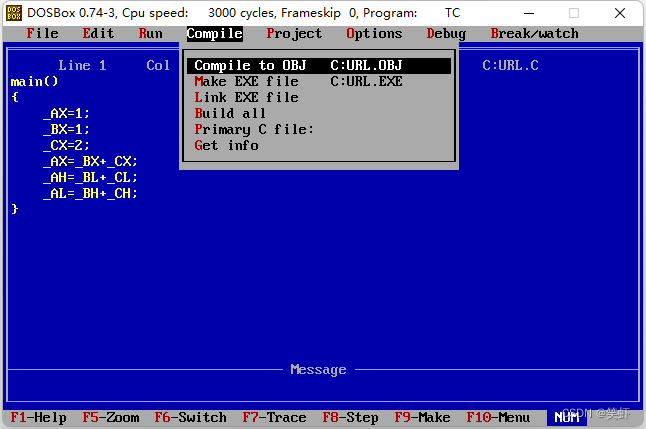
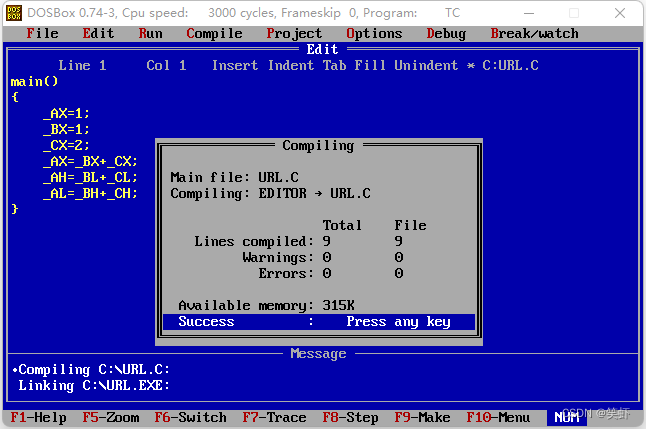
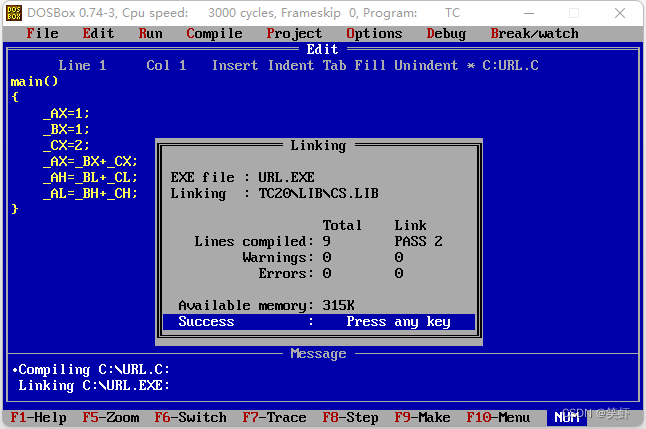
4. 连接
研究试验 2 使用寄存器
1. 编一个程序 ur1.c ( tcc 用法)
编译,连接,生成 ur1.exe
main()
{
_AX=1;
_BX=1;
_CX=2;
_AX=_BX+_CX;
_AH=_BL+_CL;
_AL=_BH+_CH;
}
| 操作 | 命令行 | 输出 |
|---|---|---|
| 编译连接 | tcc demo.c | DEMO.OBJ, DEMO.EXE |
| 编译连接:自定义EXE名称 | tcc -eAAA.exe demo.c | DEMO.OBJ, AAA.EXE |
| 只编译 | tcc -c demo.c | DEMO.OBJ |
| 只编译:自定义OBJ名称 | tcc -c -oBBB.obj demo.c | BBB.OBJ |
| 输出汇编 | tcc -S demo.c | DEMO.ASM |
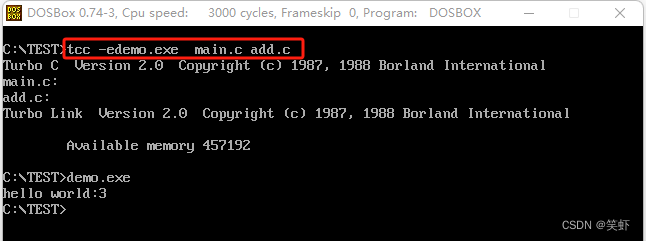
tcc 编译连接多个源文件
- main.c
int add(int a, int b);
void main() {
int c = add(1, 2);
printf("hello world:%d", c);
}
- add.c
int add(int a, int b) {
return a + b;
}
编译连接命令:tcc -edemo.exe main.c add.c 这里我设置了生成文件名 demo.exe
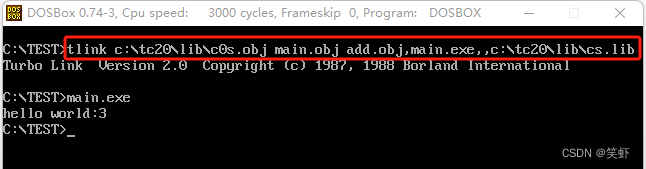
tlink 手动连接
语法:TLINK obj文件们, exe文件, map文件, lib文件
编译连接命令:tlink c:\tc20\lib\c0s.obj main.obj add.obj, main.exe,,c:\tc20\lib\cs.lib
命令中 c:\tc20 这是tc的安装位置,根据自己的情况调整。
关于编译模式有:T微、S小、C紧、M中、L大、H巨,分别对应:
默认小模式,连接时根据需要自己选。
如果换其它模式,编译时tcc也要记得换对应参数-mt, -ms, -mc, -mm, -ml, -mh
T模式没有lib
参考:stormpeach:《关于tcc、tlink的编译链接机制的研究》
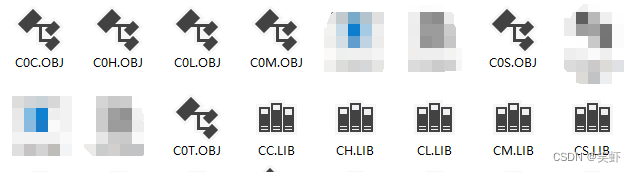
2.用 Debug 加载 ur1.exe,用u命令査看 ur1.c 编译后的机器码和汇编代码
不知道位置的可以看试下面一条,输出 main 的偏移地址
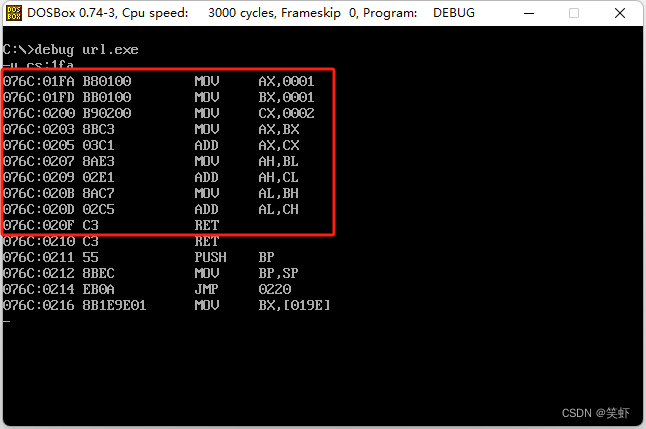
3. 用下面的方法打印出 ur1.exe 被加载运行时,main 函数在代码段中的偏移地址:
main()
{
printf("%x\n",main);
}
"%x\n"指的是按照十六进制格式打印。
思考:为什么这个程序能够打印出 main 函数在代码段中的偏移地址?
答:main 函数名,就是它的入口偏移地址,传给 printf 打印的就是 main 函数的入口偏移地址。
...
_main proc near
mov ax,offset _main
push ax
mov ax,offset DGROUP:s@
push ax
call near ptr _printf
pop cx
pop cx
@1:
ret
_main endp
...
4. 用 Debug 加载 ur1.exe,根据上面打印出的 main 函数的偏移地址,用 u 命令察看 main 函数的汇编代码。仔细找到 ur1.c 中每条 c 语句对应的汇编代码。
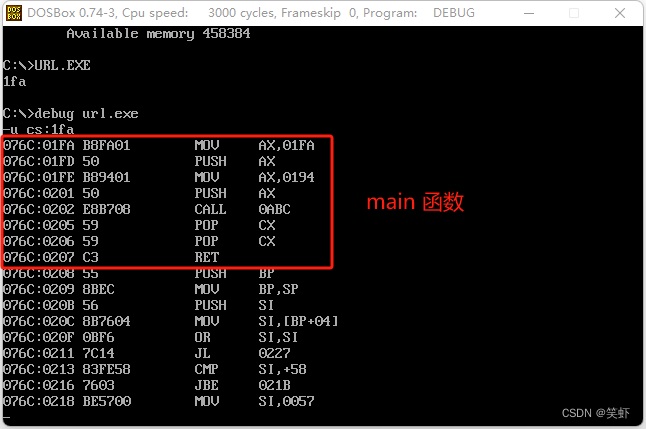
5. 通过 main 函数后面有 ret 指令,我们可以设想:C 语言将函数实现为汇编语言中的子程序。研究下面程序的汇编代码,验证我们的设想。
void f(void);
main()
{
_AX=1; _BX=1; _CX=2;
f();
}
void f(void){
_AX=_BX+_CX;
}
研究试验 3 使用内存空间
*(char *)0x2000 = 'a'; // mov byte ptr [2000], 'a'
*(char far *)0x20001000='a'; // mov bx,2000h
// mov es,bx
// mov bx,1000h
// mov byte ptr es:[bx],'a'
-
语法分析:
0x2000是一个十六进制数,它代表一个内存地址。char *表示字符指针。(char *)是类型转换,将0x2000这个数值转换成一个指向字符(char)类型的指针。*操作符在这里用于解引用指针,即访问指针所指向的内存位置的内容。- 扩展:
char* a表示声明一个变量,类型为字符指针,变量名叫a,
char *a表示声明一个叫a的指针,类型为char。
这两种写法在C语言语法中是等价的,编译器会按照相同的规则解析它们
-
含义:
- 在C语言中,
指针是一个变量,其值是一个内存地址。使用*解指针后指向的是地址里的内容。 - 整个表达式
(char *)0x2000表示将0x2000当作一个字符型指针来处理,即将该地址视为可以存储一个字符值的内存位置。 *(char *)0x2000 = 'a';这条语句试图将字符'a'存储到地址 0x2000 处。这意味着程序试图直接向内存地址0x2000写入字符'a',而不经过任何变量间接操作。
- 在C语言中,
-
使用场景:
- 直接内存操作:这种类型的表达式通常出现在对硬件进行直接控制或与特定内存区域交互的低级编程中,例如驱动程序开发、嵌入式系统编程、或者对未初始化的数据结构进行初始化等场景。
- 静态内存分配:在某些情况下,程序员可能预先知道某个内存区域可供程序使用,并直接对其赋值,尽管这不是标准C语言中的推荐做法,因为它可能导致不可预测的行为,尤其是在现代操作系统环境下,未经分配的内存直接写入可能会导致段错误(segmentation fault)或不稳定行为,因为那个地址可能不是用户程序可以合法访问的内存区域。
需要注意的是,在实际编程中,直接操作这样的内存地址应当谨慎,必须确保该地址确实是已分配给程序使用的有效内存空间。在大多数现代系统中,直接写入任意地址通常是不安全的,除非是在特定的上下文中(如内核模式或特定的安全API允许的情况下)。
1. 编一个程序 um1.c
main()
{
*(char *)0x2000='a';
*(int *)0x2000=0xF;
*(char far *)0x20001000='a';
_AX=0x2000;
*(char *)_AX='b';
_BX=0x1000;
*(char *)(_BX+_BX)='a';
*(char far *)(0x20001000+_BX)=*(char *)_AX;
}
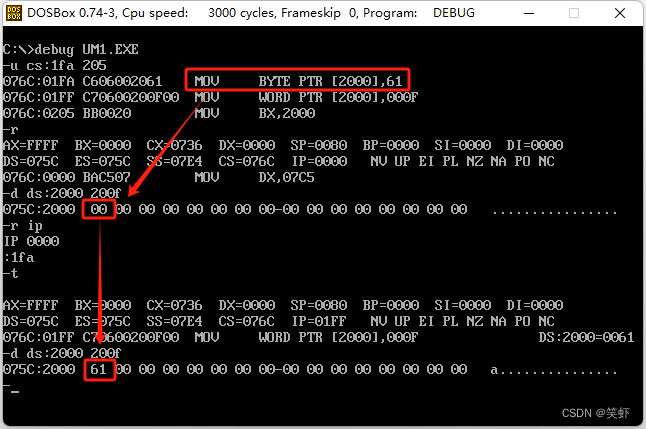
- 第一句:
*(char *)0x2000='a';在DS:2000处写入了字符a
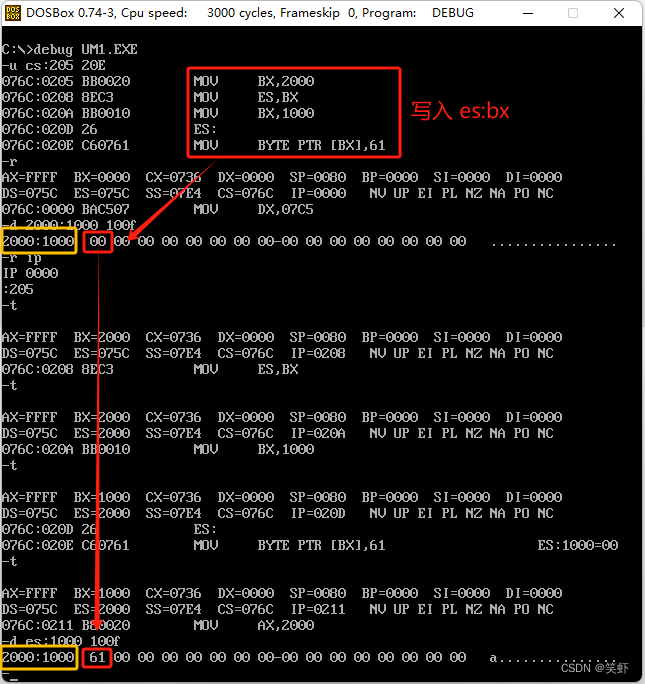
- 第三句:
*(char far *)0x20001000='a';在2000:1000处写入了字符a
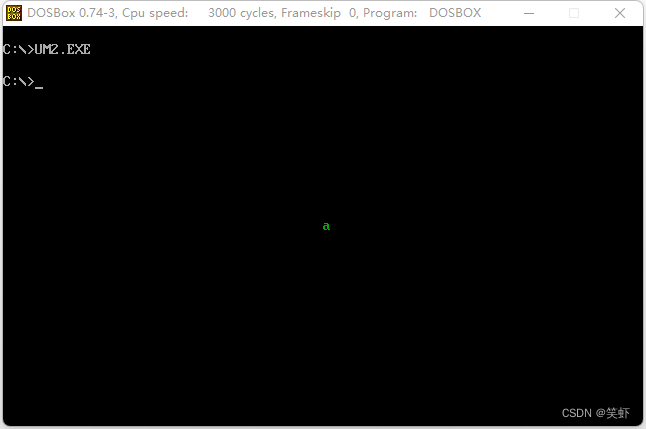
2. 编一个程序,用一条C语句实现在屏幕的中间显示一个绿色的字符 a
main(){
*(int far *)0xb80007d0=0x0261;
}
3. 分析下面程序中所有函数的汇编代码,思考相关的问题
为了接下来方便分析反汇编,这里我将16进制换成10进制,更直观点。
int a1, a2, a3;
void f(void);
main() {
int b1, b2, b3;
a1 = 161; a2 = 162; a3 = 163;
b1 = 177; b2 = 178; b3 = 179;
}
void f(void) {
int c1, c2, c3;
a1 = 4001; a2 = 4002; a3 = 4003;
c1 = 193; c2 = 194; c3 = 195;
}
TCC 输出反汇编:
ifndef ??version
?debug macro
endm
endif
?debug S "um2.c"
_TEXT segment byte public 'CODE'
DGROUP group _DATA,_BSS
assume cs:_TEXT,ds:DGROUP,ss:DGROUP
_TEXT ends
_DATA segment word public 'DATA'
d@ label byte
d@w label word
_DATA ends
_BSS segment word public 'BSS'
b@ label byte
b@w label word
?debug C E9F5568B5805756D322E63
_BSS ends
; ================= 代码段 ================
_TEXT segment byte public 'CODE'
; --------------- main 函数 ---------------
_main proc near
push bp ; 保存调用方的栈帧基址
mov bp,sp ; 将栈顶SP,传给当前栈帧基址
sub sp,6 ; 在当前栈帧开辟6个字节的空间
; 对应 int b1,b2,b3;
mov word ptr DGROUP:_a1,161 ; a1=161
mov word ptr DGROUP:_a2,162 ; a2=162
mov word ptr DGROUP:_a3,163 ; a3=163
mov word ptr [bp-6],177 ; b1=177
mov word ptr [bp-4],178 ; b2=178
mov word ptr [bp-2],179 ; b3=179
@1:
mov sp,bp ; 将(当前栈帧基址)恢复到SP,收缩栈空间
pop bp ; 恢复调用者栈帧基址
ret ; 返回调用者
_main endp
; ------------------------------------------
; 子程序 _f 对应函数 void f(void)
; --------------- f(void) 函数 -------------
_f proc near
push bp
mov bp,sp
sub sp,6
mov word ptr DGROUP:_a1,4001 ; a1=4001
mov word ptr DGROUP:_a2,4002 ; a2=4002
mov word ptr DGROUP:_a3,4003 ; a3=4003
mov word ptr [bp-6],193 ; c1=193
mov word ptr [bp-4],194 ; c2=194
mov word ptr [bp-2],195 ; c3=195
@2:
mov sp,bp
pop bp
ret
_f endp
_TEXT ends
; ================== 代码段 ================
; ============= 未初始化的数据段 ===========
; 全局变量
; 在8086环境下,C语言中的int类型通常占据2个字节(16位)
; -----------------------------------------
_BSS segment word public 'BSS'
_a1 label word ; 定义标号 _a1 类型为 word,对应 int a
db 2 dup (?) ; 分配 2 字节空间,并未初始化
_a2 label word ; int b
db 2 dup (?)
_a3 label word ; int c
db 2 dup (?)
_BSS ends
; ============ 未初始化的数据段 ============
?debug C E9
_DATA segment word public 'DATA'
s@ label byte
_DATA ends
_TEXT segment byte public 'CODE'
_TEXT ends
; 这些都被声明为公开可以被外部访问了
public _main
public _f
public _a3
public _a2
public _a1
end
1. C语言将全局变量存放在哪里?
答:全局变量声明在未初始化的数据段(BSS段)中。并且在末尾还将它们声明为 public。
2. 将局部变量存放在哪里?
答:局部变量 存放在 当前栈帧。(在堆栈中为当前函数开辟出的一段独立空间)
3. 每个函数开头的 push bp mov bp sp 有何含义?
答:这两条指令共同实现了函数栈帧的初始化,确保函数执行期间栈空间管理的独立性,且不会干扰其他栈帧。
- 基址指针寄存器
bp中存放着调用者的栈帧基址。 push bp:保存调用者的栈帧基址到堆栈,确保函数返回时能恢复原栈帧。mov bp, sp:将堆栈指针SP的当前值赋予基址指针BP,使之成为当前函数栈帧的基址,便于访问栈上局部变量和参数。
在函数返回时,还有对应的指令恢复原栈帧并返回调用者。
mov sp, bp ; 将BP的值(当前栈帧基址)恢复到SP,收缩栈空间
pop bp ; 从栈顶弹出先前保存的调用者栈帧基址,恢复BP的值
ret ; 从栈顶弹出返回地址,并跳转到该地址继续执行(返回调用者)
通过这些操作,函数调用的栈帧得以正确地创建、使用和销毁,保证了函数调用的正确性和栈空间的有效管理。
栈帧(Stack Frame)
栈帧是程序执行过程中,为函数调用而创建的一种数据结构,它主要存在于程序的调用栈(Call Stack)上。每个函数调用都会生成一个独立的栈帧,用于存储以下信息:
- 函数参数:调用函数时传递的实参值。
- 局部变量:函数内部声明的变量,其生命周期仅限于函数执行期间。
- 返回地址:函数执行完毕后需要返回的下一条指令地址。
- 前一个栈帧的基址(在某些架构中):用于恢复调用者栈帧的上下文。
.栈帧随着函数调用而创建,函数返回时销毁。它们在调用栈上自顶向下依次排列,形成一个逻辑上的堆叠结构,反映了函数调用的嵌套层次。栈帧的大小通常在编译时确定(除非有动态分配),且每个栈帧之间紧密相邻,便于快速访问和管理。
4. 分析下面程序的汇编代码,思考相关的问题。
int f(void);
int a,b,ab;
main() {
int c;
c=f();
}
int f(void) {
ab=a+b;
return ab;
}
问题:C语言将函数的返回值存放在哪里?
...
_TEXT segment byte public 'CODE'
_main proc near
push bp
mov bp,sp
sub sp,2
call near ptr _f ; 调用 f()
mov word ptr [bp-2],ax ; 从 ax 拿返回值
@1:
mov sp,bp
pop bp
ret
_main endp
_f proc near
mov ax,word ptr DGROUP:_a
add ax,word ptr DGROUP:_b
mov word ptr DGROUP:_ab,ax
mov ax,word ptr DGROUP:_ab ; 返回值放到 ax 中
jmp short @2
@2:
ret
_f endp
_TEXT ends
...
ax 不够用的情况 :
_f proc near
mov dx,word ptr DGROUP:_a+2
mov ax,word ptr DGROUP:_a
add ax,word ptr DGROUP:_b
adc dx,word ptr DGROUP:_b+2
mov word ptr DGROUP:_ab+2,dx
mov word ptr DGROUP:_ab,ax
mov dx,word ptr DGROUP:_ab+2 ; 高16位
mov ax,word ptr DGROUP:_ab ; 低16位
jmp short @2
@2:
ret
_f endp
答: ax,如果 ax 不够用还会拉上 dx:高16位存DX,低16位放AX
5. 下面的程序向安全的内存空间写入从“a”到“h”的 8 个字符,理解程序的含义,深入理解相关的知识。(注意:请自己学习、研究 malloc 函数的用法)
// 定义宏 Buffer 它是一个指向 0:200h 的字符指针,内存单元 0:200h 中保存的就是字符指针的值
#define Buffer ((char *)*(int far *)0x200)
main()
{
// 使用 malloc 函数为 Buffer 分配一块大小为20字节的动态内存。
// malloc 返回的指针(类型为void *)要强制转换为 char * 才赋值给Buffer。
// 现在 Buffer 指向一块可写、可读的连续字符数组,长度为20字节。
Buffer=(char *)malloc(20);
// 将 Buffer 数组的第11个元素(索引为10,因为数组索引从0开始)初始化为整数值 0
// 接下来的 while 循环会用它计数。类似 for 循环中的 i
Buffer[10]=0;
// 循环条件 Buffer[10] != 8 就继续,每次 Buffer[10]自增 1。从 0 到 7 共 8 次
// 从 Buffer[0] 开始存入 'a' + Buffer[10] 的结果,
// 计算时用字符的ascii码 97 与 Buffer[10] 相加。 97 到 104 正好是 a 到 h,
// 'a' + 0 = 'a'
// ...
// 'a' + 7 = 'h'
while(Buffer[10]!=8){
Buffer[Buffer[10]]='a'+Buffer[10];
Buffer[10]++;
}
// 调用 free 函数释放之前为 Buffer 分配的动态内存
free(Buffer);
}
分析:
- 定义宏 Buffer
预处理器指令#define用来定义宏,格式:#define 宏名 宏替换文本- 首先:
(int far *)0x200是一个指向内存地址0x200的远指针。 - 然后: 使用
*对这个远指针进行解引用得到一个整数值(int)。 - 最后: 将这个
整数值强制转换为一个字符型指针(char *)。
总之:Buffer被定义为一个字符型指针,指针的值是0x200中保存的内容。
- 首先:
- malloc() 函数
函数malloc()是C语言中用于动态内存分配的核心函数之一,它属于标准库函数,通常包含在stdlib.h头文件中。- 功能:
malloc()函数的主要功能是在程序运行时动态地为程序分配一块指定大小的内存块。 - 返回值:
malloc()函数返回一个指向所分配内存块起始位置的指针。
如果分配成功,返回的指针类型为void *,这意味着它可以被转换为任何类型的指针(例如,int *、char *、struct MyStruct *等),以符合实际内存块的用途。
如果内存分配失败(例如,系统资源不足或请求的内存过大)返回NULL。
- 功能:
- 反汇编分析
...略
_TEXT segment byte public 'CODE'
_main proc near
; Buffer=(char *)malloc(20);
mov ax,20
push ax ; 20压栈作为 malloc 参数
call near ptr _malloc ; 调用 malloc 申请 20 字节的内存空间
pop cx ; 弹出调用函数前被压入栈中的参数 20
xor bx,bx ; 清零 bx
mov es,bx ; 设置段地址
mov bx,512 ; 设置偏移地址
; 这里的 512 就是 Buffer 宏定义时的 0x200
mov word ptr es:[bx],ax ; word ptr es:[bx] 就是 Buffer 指针对应的内存位置
; ax 就是将 malloc 返回的值
; --------------------------
; 这4句固定搭配,拿到 Buffer
; 其实就是算出它的偏移量给 bx
; --------------------------
xor bx,bx
mov es,bx
mov bx,512
mov bx,word ptr es:[bx] ; bx 再在就是动态分配的那 20 字节空间的首地址偏移
; --------------------------
; 这句对应 Buffer[10]=0;
; byte ptr [bx] 就是 Buffer
; byte ptr [bx+10] 就是 Buffer[10]
; --------------------------
mov byte ptr [bx+10],0
jmp short @2 ; @4 后面是循环体,开始前先跳 @2 那里是循环条件
@4:
; --------------------------
; Buffer[Buffer[10]]='a'+Buffer[10]; 的 = 号右边:
; 这4句固定搭配,拿到 Buffer
; --------------------------
xor bx,bx
mov es,bx
mov bx,512
mov bx,word ptr es:[bx]
; --------------------------
; 'a'+Buffer[10]
; --------------------------
mov al,byte ptr [bx+10]
add al,97
; --------------------------
; Buffer[Buffer[10]]='a'+Buffer[10]; 的 = 号左边:
; 这4句固定搭配,拿到 Buffer
; --------------------------
xor bx,bx
mov es,bx
mov bx,512
mov bx,word ptr es:[bx]
push ax ; al 里存着 'a'+Buffer[10] 的结果
push bx ; bx 是 Buffer 的偏移量
xor bx,bx ; 清零
; --------------------------
; 拿到 Buffer[10] 的值存在 ax (后面用它当索引)
; --------------------------
mov es,bx
mov bx,512
mov bx,word ptr es:[bx]
mov al,byte ptr [bx+10]
cbw ; 将 AL 扩展为 AX 符号不变。
pop bx ; 取出 Buffer 的偏移量
add bx,ax ; Buffer[ax] 也就是 Buffer[Buffer[10]]
; --------------------------
; 将等号右边的结果赋值给 Buffer[Buffer[10]]
; --------------------------
pop ax ; 恢复 ax (等号右边的结果)
mov byte ptr [bx],al ; 赋值
; --------------------------
; 这4句固定搭配,拿到 Buffer
; --------------------------
xor bx,bx
mov es,bx
mov bx,512
mov bx,word ptr es:[bx]
inc byte ptr [bx+10] ; 对应 Buffer[10]++;
@2:
; --------------------------
; 这4句固定搭配,拿到 Buffer
; --------------------------
xor bx,bx
mov es,bx
mov bx,512
mov bx,word ptr es:[bx]
cmp byte ptr [bx+10],8 ; 如果 Buffer[10]!=8
jne @4 ; 继续循环
@3:
; --------------------------
; 这4句拿到 Buffer 压栈作为 free 的参数
; --------------------------
xor bx,bx
mov es,bx
mov bx,512
push word ptr es:[bx]
call near ptr _free ; 对应 free(Buffer);
pop cx ; 清理 调用 free 压的参数
@1:
ret
_main endp
_TEXT ends
...略
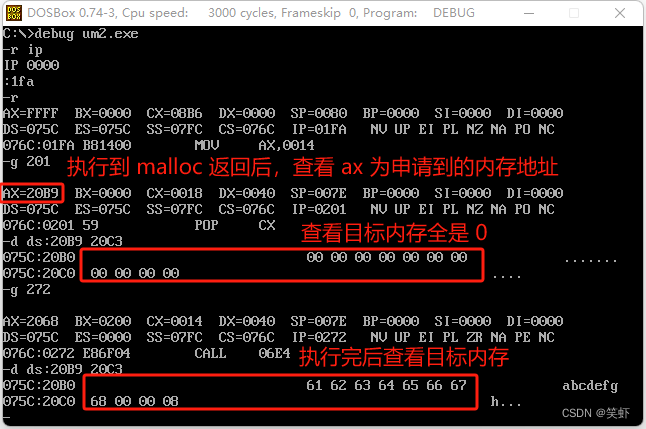
注意:最后我是在释放内存前查看的。一旦释放,就有可能被其它程序修改了。
研究试验 4 不用 main 函数编程
1. 编译,连接这段代码思考相关问题
f()
{
*(char far *)(0xb8000000+160*10+80)='a';
*(char far *)(0xb8000000+160*10+81)=2;
}
1. 编译和连接哪个环节会出问题?
答:编译成功,连接失败。
2. 显示出的错误信息是什么?
答: 没定义 main
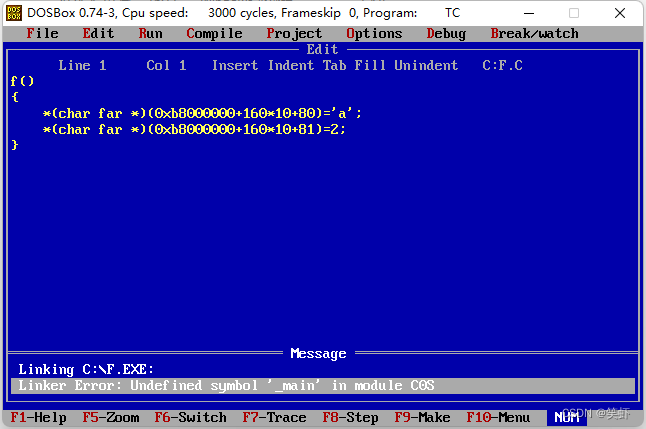
3. 这个错误信息可能与哪个文件相关?
答: f.exe ? 生成失败算相关吗?错误信息中提至的 C0S 算吗?
2.用学习汇编语言时使用的 link.exe 对 tc.exe 生成的 f.obj 文件进行连接,生成f.exe。用 Debug 加载 f.exe,察看整个程序的汇编代码。思考相关的问题。
分析:
连接成功但有警告:LINK warning L4038:program has no starting address
1. f.exe 的程序代码总共有多少字节?
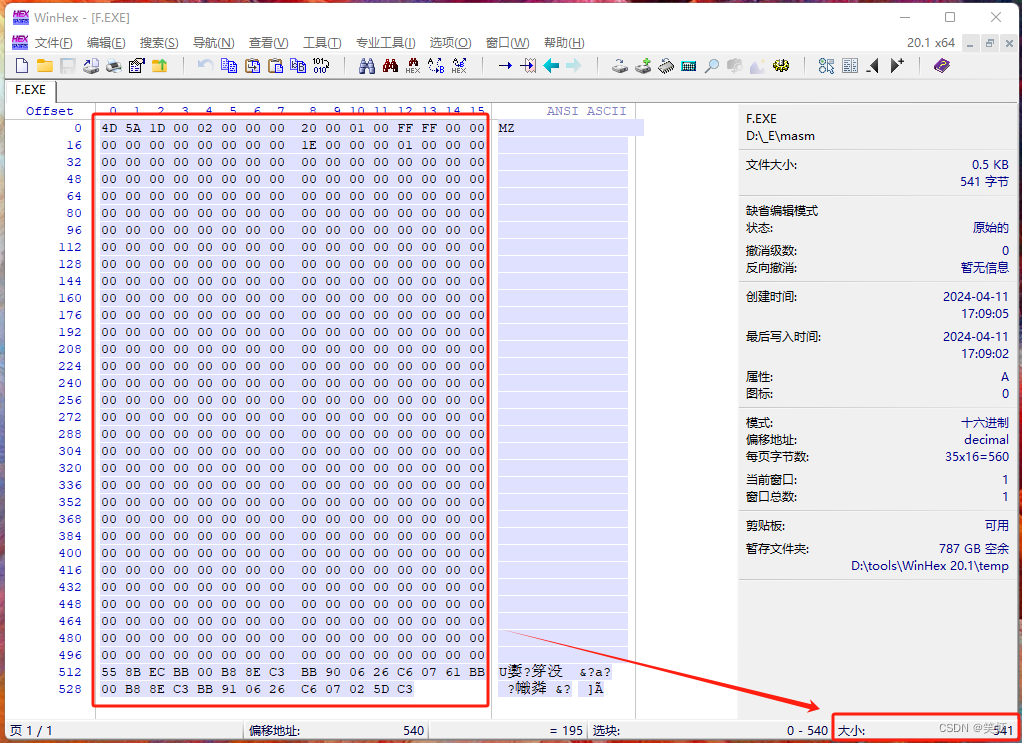
答: f.exe 的程序有 541 字节。实际的代码长度 29 字节。
去掉创建栈帧 push bp,mov bp sp 的4字节,
去掉还原建栈帧的 pop bp 的 1 字节,函数 f() 长度 25 字节。
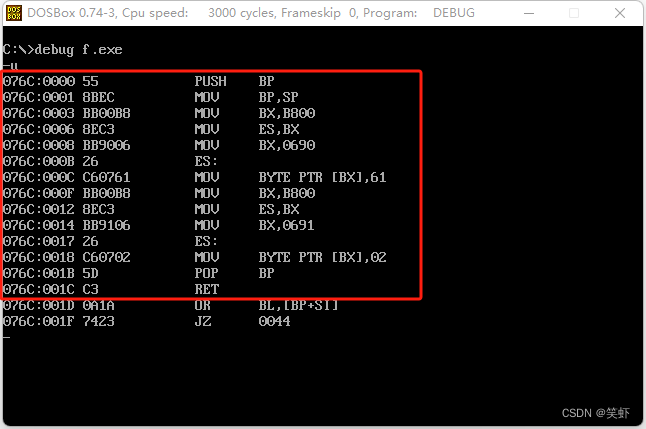
2. f.exe 的程序能正确返回吗?
答: 执行后卡死,无法返回。
3. f 函数的偏移地址是多少?
答: 0
3. 写一个程序 m.c
main()
{
*(char far *)(0xb8000000+160*10+80)='a';
*(char far *)(0xb8000000+160*10+81)=2;
}
用 tc.exe 对 m.c 进行编译,连接,生成 m.exe,用 Debug 察看 m.exe 整个程序的汇编
代码。思考相关的问题。
1. m.exe 的程序代码总共有多少字节?
答: 共 25 字节。与 f 相比少了创建和还原栈帧的4字节
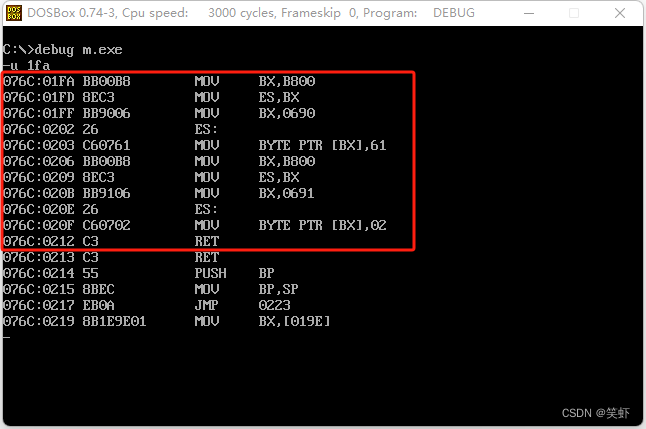
2. m.exe 能正确返回吗?
答: 正常返回
3. m.exe 程序中的 main 函数和 f.exe 中的f函数的汇编代码有何不同?
答: 除了 _main 和 _f 标号名称不同外,f函数多了一句jmp short @1,但从逻辑上看貌似没有啥影响。
4. 用 Debug 对 m.exe 进行跟踪:
① 找到对 main 函数进行调用的指令的地址;
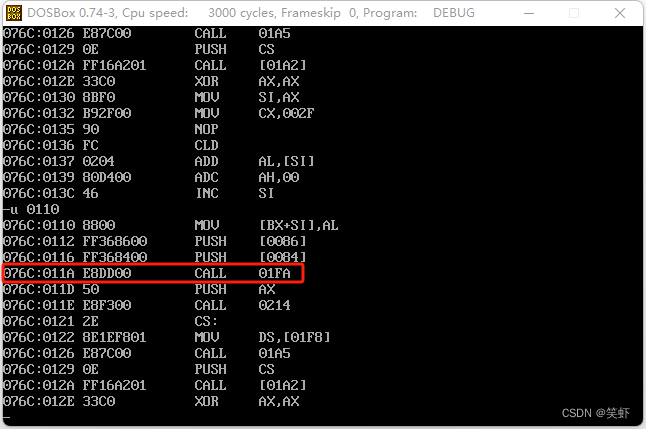
答: 先 g 跳到 main 函数的 ret 指令处,
再 t 追踪,返回到 main 调用者 076C:011D,u 110 往回查看几行。找到 call 01FA
②找到整个程序返回的指令。注意:使用g命令和p命令。
答: 先 g 11D 来到 main 返回的位置,向下走:
076C:011E CALL 0214
076C:0217 JMP 0223
076C:022E CALL [0194]
076C:0213 RET
076C:0232 CALL [0196]
076C:0213 RET
076C:0236 CALL [0198]
076C:0213 RET
076C:023A PUSH [BP + 04]
076C:023D CALL 0121
076C:0126 CALL 01A5
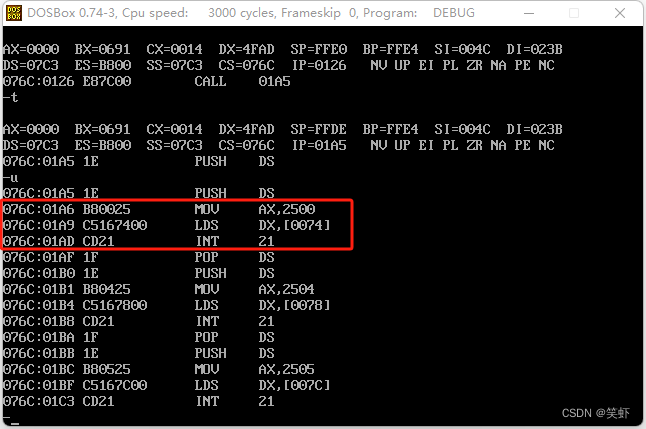
在 076C:01AD INT 21 这里有个中止进制,但程序并没有退出来,继续…
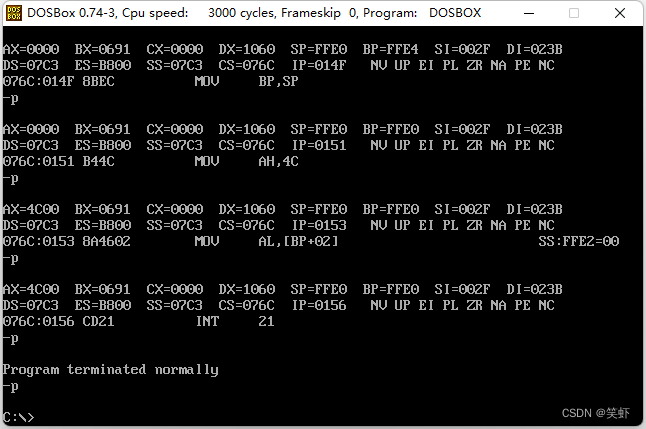
最终在 076C:0156 INT 21 (4Ch带返回码方式的终止进程)这里整个程序才完全返回。
5. 思考如下几个问题
1. 对 main 函数调用的指令和程序返回的指令是哪里来的?
答: 是 c0s.obj
2. 没有 main 函数时,出现的错误信息里有和 c0s 相关的信息;而前面在搭建开发环境时,没有 c0s.obj 文件 tc.exe 就无法对程序进行连接。是不是 tc.exe 把 c0s.obj 和用户程序的 .obj 文件一起进行连接生成 .exe 文件?
答: 是
3. 对用户程序的 main 函数进行调用的指令和程序返回的指令是否就来自 c0s.obj 文件?
答: 是
4. 我们如何看到 c0s.obj 文件中的程序代码呢?
答: 参考下面的第 6 条(用 link.exe 对 c:\TC20\LIB 目录下的 c0s.obj 进行连接,生成 c0s.exe。)
然后 debug c0s.exe
5. c0s.obj 文件里有我们设想的代码吗?
答: 有
6. 用 link.exe 对 c:\minic(我的在 c:\TC20\LIB) 目录下的 c0s.obj 进行连接,生成 c0s.exe。
用 Debug 分别察看 c0s.exe 和 m.exe 的汇编代码。注意:从头开始察看,两个文件中的程序代码有何相同之处?
答: 我还是直接对比一下吧
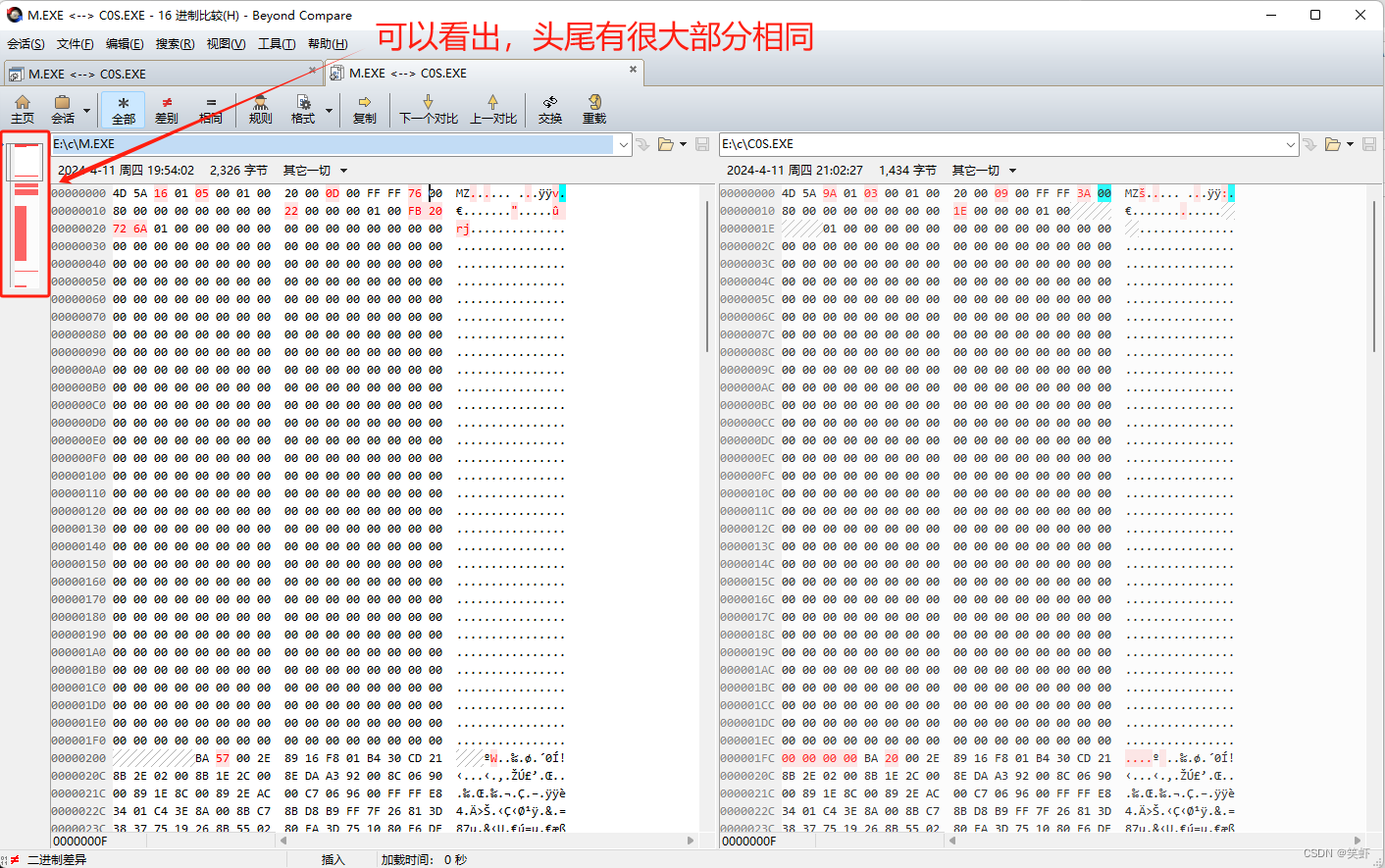
补充说明一下,我连接时报错了,但还是生成了 exe
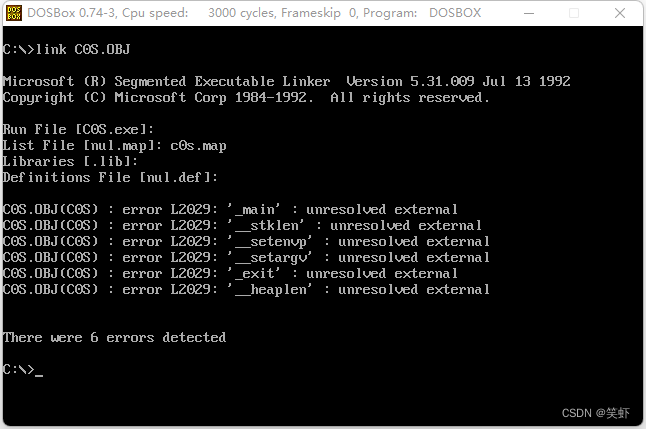
7. 用 Debug 找到 m.exe 中调用 main 函数的 call 指令的偏移地址,从这个偏移地址开始向后察看 10 条指令;然后用 Debug加载 c0s.exe,从相同的偏移地址开始向后察看 10条指令。对两处的指令进行对比。
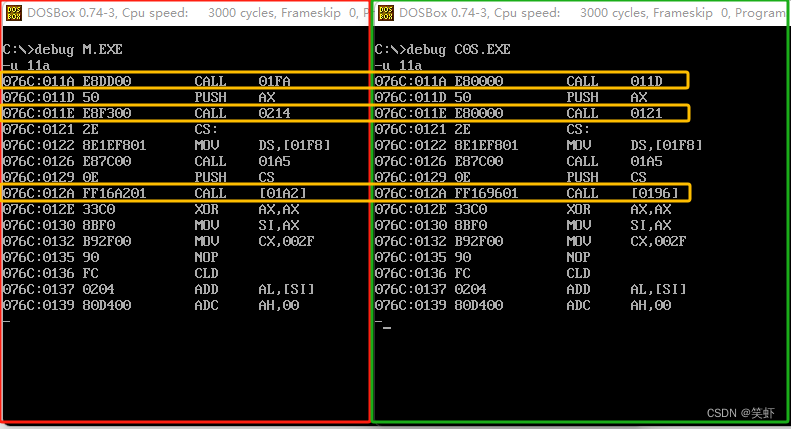
8. tc.exe(Turbo C 编译器)编译器连接器将 c0s.obj 和用户编写的 .obj 文件链接生成 .exe 文件的过程及其内部运行机制,大致如下:
-
连接过程:
tc.exe将c0s.obj(含系统提供的初始化代码)与用户编写的.obj文件(包含用户程序代码)进行连接,生成可执行的.exe文件。
-
程序运行流程:
- 启动阶段:执行从
c0s.obj加载的初始化程序,负责完成以下任务:- 申请必要的系统资源;
- 设置数据段寄存器
DS、堆栈段寄存器SS等;
- 用户程序启动:初始化程序调用用户代码中的
main函数,标志着用户程序开始运行。 - 用户程序执行:用户程序在
main函数中执行其逻辑。 - 用户程序退出:
main函数返回后,控制权交还给c0s.obj中的后续代码。 - 清理与退出:
c0s.obj中的程序执行资源释放、环境恢复等操作,最后通过调用 DOS 系统中断int 21h的4ch功能号实现程序的正常退出。
- 启动阶段:执行从
-
C程序从
main函数开始的保障机制:- 系统支持:C 开发系统(如 Turbo C)提供了必要的初始化和退出处理程序,存储在诸如
c0s.obj这样的系统对象文件中。 - 链接要求:用户编写的
.obj文件必须与包含系统支持代码的.obj文件(如c0s.obj)一起进行链接,形成完整的可执行文件。 - 主函数调用:
c0s.obj中的代码负责在初始化完成后调用用户代码中的main函数,确保程序从main函数开始执行。
- 系统支持:C 开发系统(如 Turbo C)提供了必要的初始化和退出处理程序,存储在诸如
-
灵活启动点:
- 修改启动行为:理论上,通过改写
c0s.obj中的代码,使其调用用户程序中的其他函数而非main函数,用户可以编写不依赖于main函数作为入口点的C程序。
- 修改启动行为:理论上,通过改写
总结来说,Turbo C 编译器通过链接包含系统初始化与退出处理代码的 c0s.obj 与用户编写的 .obj 文件,构建出遵循标准C语言规范(即从 main 函数开始执行)的可执行程序。这种机制确保了C程序的正确初始化、资源管理以及与操作系统的交互。同时,通过修改 c0s.obj,理论上可以自定义程序的启动行为,突破仅从 main 函数开始执行的限制。
assume cs:code
data segment
db 128 dup (0)
data ends
code segment
start: mov ax,data
mov ds,ax
mov ss,ax
mov sp,128
call s
mov ax,4c00h
int 21h
s:
; 编译连接后 f.c 对应的汇编代码就直接拼在这后面。
; 所以上面 call s 后就是调用 f() 了
code ends
end start
9. 用 tc.exe 将 f.c 重新进行编译,连接,生成 f.exe。
-
这次能通过连接吗?
答: 能
-
f.exe可以正确运行吗?
答: 可以
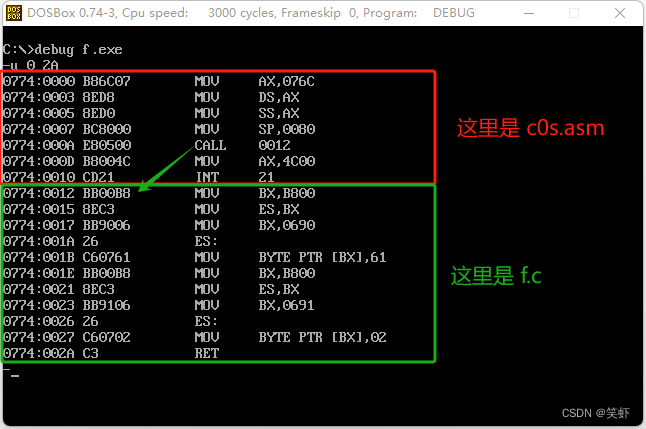
-
用
Debug察看f.exe的汇编代码。
答: 给你:
10. 在新的 c0s.obj 的基础上,写一个新的 f.c,向安全的内存空间写入从“a”到“h”的8个字符。分析、理解 f.c。
#define Buffer ((char *)*(int far *)0x200)
f()
{
Buffer=0;
Buffer[10]=0;
while(Buffer[10]!=8){
Buffer[Buffer[10]]='a'+Buffer[10];
Buffer[10]++;
}
}
debug 查看反汇编:
; ======================== c0s.obj ========================
076C:00000000 B8060E mov ax,076C
076C:00000003 8ED8 mov ds,ax
076C:00000005 8ED0 mov ss,ax
076C:00000007 BC8000 mov sp,0080
076C:0000000A E80500 call 00000012 ($+5)
076C:0000000D B8004C mov ax,4C00
076C:00000010 CD21 int 21
; ========================== f.c ==========================
; ---------------------------------------------------------
; 对应:Buffer=0;
; ---------------------------------------------------------
076C:00000012 33DB xor bx,bx
076C:00000014 8EC3 mov es,bx
076C:00000016 BB0002 mov bx,0200
076C:00000019 26C7070000 mov word es:[bx],0000 es:[0200]=0000
; ---------------------------------------------------------
; 对应:Buffer[10]=0;
; ---------------------------------------------------------
076C:0000001E 33DB xor bx,bx
076C:00000020 8EC3 mov es,bx
076C:00000022 BB0002 mov bx,0200
076C:00000025 268B1F mov bx,es:[bx] es:[0200]=0000
076C:00000028 C6470A00 mov byte [bx+0A],00 ds:[000A]=0000
; ---------------------------------------------------------
; 对应:while (循环条件在下面 076C:0000006A)
; ---------------------------------------------------------
076C:0000002C EB3C jmp short 0000006A ($+3c)
; ---------------------------------------------------------
; 对应:{ (while 循环体从这开始)
; ---------------------------------------------------------
076C:0000002E 33DB xor bx,bx
076C:00000030 8EC3 mov es,bx
076C:00000032 BB0002 mov bx,0200
076C:00000035 268B1F mov bx,es:[bx] es:[0200]=0000
076C:00000038 8A470A mov al,[bx+0A] ds:[000A]=00 ; al=Buffer[10]
076C:0000003B 0461 add al,61 ; al='a'+al
076C:0000003D 33DB xor bx,bx
076C:0000003F 8EC3 mov es,bx
076C:00000041 BB0002 mov bx,0200
076C:00000044 268B1F mov bx,es:[bx] es:[0200]=0000
076C:00000047 50 push ax
076C:00000048 53 push bx
076C:00000049 33DB xor bx,bx
076C:0000004B 8EC3 mov es,bx
076C:0000004D BB0002 mov bx,0200
076C:00000050 268B1F mov bx,es:[bx] es:[0200]=0000
076C:00000053 8A470A mov al,[bx+0A] ds:[000A]=00
076C:00000056 98 cbw
076C:00000057 5B pop bx
076C:00000058 03D8 add bx,ax
076C:0000005A 58 pop ax
076C:0000005B 8807 mov [bx],al ds:[0000]=00 ; 存入字符
; ---------------------------------------------------------
; 对应:Buffer[10]++;
; ---------------------------------------------------------
076C:0000005D 33DB xor bx,bx
076C:0000005D 33DB xor bx,bx
076C:0000005F 8EC3 mov es,bx
076C:00000061 BB0002 mov bx,0200
076C:00000064 268B1F mov bx,es:[bx] es:[0200]=0000
076C:00000067 FE470A inc byte [bx+0A] ds:[000A]=1D9F ; 索引++
; ---------------------------------------------------------
; 对应:while 的循环条件 Buffer[10]!=8
; ---------------------------------------------------------
076C:0000006A 33DB xor bx,bx
076C:0000006C 8EC3 mov es,bx
076C:0000006E BB0002 mov bx,0200
076C:00000071 268B1F mov bx,es:[bx] es:[0200]=0000
076C:00000074 807F0A08 cmp byte [bx+0A],08 ds:[000A]=0000
076C:00000078 75B4 jne 0000002E ($-4c)
; ---------------------------------------------------------
; 对应:}
; ---------------------------------------------------------
076C:0000007A C3 ret
研究试验 5 函数如何接收不定数量的参数
1.分析程序 a.c
用 tc.exe 对 a.c 进行编译,连接,生成 a.exe。用 Debug 加载 a.exe,对函数的汇编代码进行分析。解答这两个问题:main 函数是如何给 showchar 传递参数的?showchar 是如何接收参数的?
void showchar(char a, int b);
main()
{
showchar('a',2);
}
void showchar(char a, int b)
{
*(char far *)(0xb8000000+160*10+80)=a;
*(char far *)(0xb8000000+160*10+81)=b;
}
答: main 将参数压入栈中传给 showchar,showchar 按偏移量从栈帧取出两个参数。

; ========================== main ==========================
mov ax,2 ; 首先参数 2 入栈
push ax
mov al,97 ; 其次参数 'a' 入栈
push ax
call near ptr _showchar ; 调用函数 showchar
pop cx
pop cx
ret
; ======================== showchar ========================
push bp ; 保护调用方栈帧基址
mov bp,sp ; 在栈顶创建新栈帧基址
mov al,byte ptr [bp+4] ; 从栈中取出 'a'
mov bx,0B800h ; 写入内存 B800:0690
mov es,bx
mov bx,0690
mov byte ptr es:[bx],al
mov al,byte ptr [bp+6] ; 从栈中取出 2
mov bx,0B800h ; 写入内存 B800:0691
mov es,bx
mov bx,0691
mov byte ptr es:[bx],al
pop bp
ret
2. 分析程序 b.c
void showchar(int,int,...);
main()
{
showchar(8,2,'a','b','c','d','e','f','g','h');
}
void showchar(int n, int color, ...)
{
int a;
for(a=0; a!=n; a++)
{
*(char far *)(0xb8000000+160*10+80+a+a)=*(int *)(_BP + 8 + a + a);
*(char far *)(0xb8000000+160*10+81+a+a)=color;
}
}
深入理解相关的知识。思考:
-
showchar函数是如何知道要显示多少个字符的?
答: 传给showchar的第一个参数就是字符数。 -
printf函数是如何知道有多少个参数的?
答: 调用printf对应CALL 0AC1。
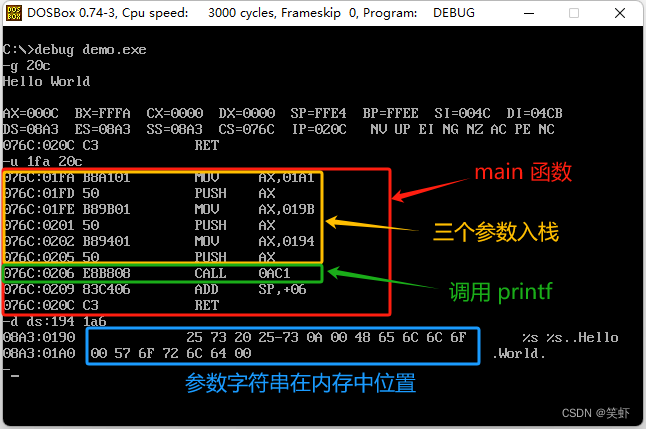
1. 参数为单个字符串时,直接地址放入ax给printf。
2. 参数为多个字符串时,压栈传给printf。(当前情况)
3.printf("%s %s\n", "Hello", "World");时三个参数被压入栈中传给printf
3.1.printf会根据第一个参数字符串中的格式说明符 %的个数来知晓参数数量。
3.2. 遍历第一个参数,每遇到一次%就从对应的位置,取一个参数来处理。
3. 实现一个简单的 printf 函数,只需要支持 %c、%d 即可。
masm myprintf.asm;编译出myprintf.objtcc -c main.c编译出main.objtlink c0s.obj main.obj myprintf.obj, main.exe,,cs.lib连接出main.exe
- 编译,连接辅助bat脚本(我的 tc2.0 在
c:\tc20)
cls
del main.exe
del main.map
del *.obj
masm myprintf.asm;
tcc -c main.c
tlink c:\tc20\lib\c0s.obj main.obj myprintf.obj, main.exe,,c:\tc20\lib\cs.lib
myprintf.asm
用汇编实现一个 myprintf 方法,供 turbo c 调用。
BUFF_LEN EQU 50h
_TEXT segment byte public 'CODE'
assume cs:_TEXT
public _myprintf ; 声明为外部可用
_myprintf proc
push bp
mov bp,sp
sub sp,128 ; 开辟 128 的局部空间(SP 到 BP 之间这一段)
push si
push di
; [bp-128]存放标志【-】:左对齐。若指定宽度,数据会在指定宽度内左对齐,右侧填充值。
; [bp-127]存放标志【+】:始终显示正负号。+1, -1, +0
; 【空格】:正数前面输出空格,负数前仍然输出 -
; [bp-126]:未使用
; [bp-125]存放标志【0】:用 0 填充宽度。适用于数值输出,且通常与宽度修饰符一起使用。
; [bp-124]存修饰符【*】:参数指定宽度,类型 int 。printf("%*c", 5, 'A');
; [bp-123]~[bp-122]存:显示宽度 初始化为0
mov word ptr [bp-123],0
; [bp-100]存放缓冲区长度,默认 BUFF_LEN,满了就打印一次
mov [bp-100],BUFF_LEN
; [bp-102] 存缓冲区长度的地址
lea di,[bp-100] ; 拿出地址
mov [bp-102],di ; 存进去
lea di,[bp-99] ; di 指向缓冲区首字地址
; [bp-4]~[bp-3]存: 格式说明字符串遍历到第几个字符(字符的偏移量)
mov si,[bp+4] ; 默认从参数1开始开头开始,si 取参数1地址
mov [bp-4],si ;
mov [bp-8],di ; 存缓冲区首字地址
; [bp-6]~[bp-5]缓存:待处理的参数地址(初始是第2个然后是3、4、5...)
lea ax,[bp+6]
mov [bp-6],ax
; -------------- 遍历格式说明字符串 --------------
loopp1:
mov [bp-4],si ;
mov [bp-8],di ; 更新待处理的参数地址
; 从参数1字符串中,读取一个字符到 al
; 如果取到 0 表示格式说明字符串结束跳 ctrl_string_end
; 如果取到格式说明符 % 调用 ctrl_string 解析格式说明符
; 如果取到普通字符,存入缓冲区
lodsb ; 串操作从 ds:[si] 取一个字节,然后 si++
; 每次开始解析格式说明符前都清一下标志位
mov byte ptr [bp-128],0 ; 80
mov byte ptr [bp-127],0 ; 7F
mov byte ptr [bp-125],0 ; 7D
mov byte ptr [bp-124],0 ; 7C
mov word ptr [bp-123],0 ; 7B
or al,al
je ctrl_string_end
cmp al,'%'
je ctrl_string
normal_char: ; 普通字符
push [bp-102] ; 缓冲区长度地址
call append_char_to_buffer
jmp loopp1 ; 继续遍历下一个格式说明符
ctrl_string: ; 格式说明符
call parse_ctrl_string
jmp loopp1
; 格式说明字符串结束
ctrl_string_end:
push [bp-102] ; 缓冲区长度地址
call print_buffer
err:
pop di
pop si
mov sp,bp ; 释放局部空间
pop bp ; 还原栈帧基址为调用者
ret
_myprintf endp
; ====================== 向缓冲区追加字符 ======================
; 参数:di ds:[di] 指向追加的位置
; 参数:al 要追加的字符
; 参数:[bp+4] 缓冲区长度地址
; --------------------------------------------------------------
append_char_to_buffer proc
push bp
mov bp,sp
mov bx,[bp+4] ; 缓冲区长度地址
mov [di],al ; 字符存入缓冲区
inc di ; 指向缓冲区中下一个字符位置
mov bx,[bp+4]
; 检测缓冲区长度如果 >0 表示没满,继续遍历下一个格式说明符
dec byte ptr [bx] ; 长度 - 1,
jg append_char_to_buffer_end ; 如果 >0 表示未满,本次追加结束
push bx
call print_buffer ; 否则已满,调用 print_buffer 清空弹夹
append_char_to_buffer_end:
mov sp,bp
pop bp
ret 2
append_char_to_buffer endp
; ====================== 向缓冲区追加字符 ======================
; ========================== 填充字符 ==========================
; 参数:dl 要追加的字符
; 参数:di ds:[di] 指向追加的位置
; 参数:cx 填充个数
; --------------------------------------------------------------
pad_char proc
cmp cx,0
jbe pad_char_end
pad_char_start:
mov [di],dl
inc di
loop pad_char_start
pad_char_end:
ret
pad_char endp
; ========================== 填充字符 ==========================
; ====================== 输出并清空缓冲区 ======================
; 参数:di 缓冲区当前位置
; 参数:[bp+4] 缓冲区长度地址
; 缓冲区的首地址 = 长度地址 + 1
; --------------------------------------------------------------
print_buffer proc
push bp
mov bp,sp
push ax
push bx
push dx
mov [di],'$' ; 按 09h 需求,在后面加上结束符
mov dx,[bp+4] ; 缓冲区长度地址
;mov bx,dx
inc dx ; 缓冲区的首地址
;add dx,2
mov ah,09h ; 在Teletype模式下显示字符串
int 21h
mov word ptr [bp+4],BUFF_LEN ; 重置缓冲区长度
mov di,dx ; 重置di指向缓冲区起始位置
pop dx
pop bx
pop ax
mov sp,bp
pop bp
ret 2
print_buffer endp
; ====================== 输出并清空缓冲区 ======================
; ======================= 解析格式说明符 =======================
; 遇到 % 的处理逻辑。将解析出来的标志、打印宽度,存到 [bp-128] 开始的一系列内存单元中
; --------------------------------------------------------------
; 参数:ds:si 指向要解析的目标字符串
; 返回:ax 返回数值
; --------------------------------------------------------------
parse_ctrl_string proc
push bx
push cx
parse_ctrl_string_start:
lodsb
cmp al,'%' ; %=25 %后面的 % 作为普通字符直接显示
je normal_percent_sign
; 修饰项(用于说明宽度、小数位、填充情况)
; 标志判断
cmp al,'-' ; -=2D 左对齐
je left_justify
cmp al,'+' ; +=2B 【+】:始终显示正负号。+1, -1, +0
je always_signs
cmp al,' ' ; =20【 】:只显示负号(正数前面输出空格)
je only_negative
cmp al,'0' ; 0=30【0】:用 0 填充宽度(只对数字生效)
je zero_padding
cmp al,'*' ; *=2A 传参指定宽度
je set_print_span
cmp al,'0' ; 0=30 格式说明字符串中指定的宽度
jb numend ; 小于 0 非数字,跳 numend
cmp al,'9' ; 9=39 格式说明字符串中指定的宽度
jg numend ; 大于 9 非数字,跳 numend
jmp parset_print_span ; 否则将数字解析为打印宽度
numend:
; 格式说明符
format_start:
cmp al,'c' ; c=63 显示字符
je show_char
cmp al,'d' ; d=64 显示整数
je show_digit
or al,al ; 读到格式说明字符串结束
je parse_ctrl_string_end ; 跳返回
; 不是任何格式说明符,则从上一次遇到的 % 开始到字符串结尾,全当普通字符(通畅是格式说明符写错了)
pcs_normal_char:
; 恢复到上一个 % 时的状态:si,[bp-102], di
mov si,[bp-4] ; 从上一次遇到的 % 的位置
mov al,[si]
inc si
sub di,[bp-8] ; 当前位置 - %位置 = 要回退的长度
sub [bp-102],di ; 原长度 - 要回退的长度 = 新长度
mov di,[bp-8] ; 原%位置放回 di
pcs_normal_char_s:
push [bp-102] ; 缓冲区长度地址
call append_char_to_buffer
lodsb
or al,al ; 没读到字符串结束
jne pcs_normal_char_s ; 就一直继续
dec si ; 为了返回上一层也能正常退出,后退一位,让上一层也读到 0 就能正常退出了
jmp parse_ctrl_string_end ; 全部作为普通字符输出完成后,跳结束
normal_percent_sign: ; 普通字符 %
push [bp-102] ; 缓冲区长度地址
call append_char_to_buffer
jmp parse_ctrl_string_end ; 本次%已经消费,跳结束
; 标志只需要先存下来
left_justify: ; 左对齐:保存标志,继续遍历下一个格式说明符
mov [bp-128],al
jmp parse_ctrl_string_start
always_signs: ; 【+】:始终显示正负号。+1, -1, +0
mov [bp-127],al
jmp parse_ctrl_string_start
only_negative: ; 【 】:只显示负号(正数前面输出空格)
mov [bp-127],al
jmp parse_ctrl_string_start
zero_padding: ; 【0】:用 0 填充宽度(只对数字生效)
mov [bp-125],al
jmp parse_ctrl_string_start
parset_print_span: ; 解析打印宽度
call _parse_int
jmp parse_ctrl_string_start
set_print_span: ; * 参数指定宽度
mov [bp-124],al
; 既然传了宽度参数,那就取出来放到[bp-123]待用
mov bx,[bp-6] ; 取出宽度参数地址
mov cx,[bx] ; 取出宽度参数
mov word ptr [bp-123],cx; 存到宽度位置
add [bp-6],2 ; 指向下一个待处理参数
lodsb ; * 号后只认格式说明符,取一个字符后
jmp format_start ; 跳 format_start 继续判断
; 格式说明符,按要求处理
show_char: ; 字符格式
call do_show_char
jmp parse_ctrl_string_end
show_digit: ; 整数格式
call do_show_digit
parse_ctrl_string_end:
pop cx
pop bx
ret
parse_ctrl_string endp
; ======================= 解析格式说明符 =======================
; ======================= 打印格式为字符 =======================
; 参数:al 待打印的字符
; 参数:di 缓冲区当前可用位置的地址
; --------------------------------------------------------------
do_show_char proc
push bx
push cx
push dx
mov cx,[bp-123] ; 从统计结果中取出宽度
cmp cx,0
jbe align_o ; 小等于 0 说明没指定
dec cx ; 否则:宽度 - 1字符 = 填充长度
align_o:
mov bx,[bp-6] ; 取出字符(对于 c 存的是字符值)
mov al,[bx]
mov dl,' ' ; 设置填充字符
cmp [bp-128],'-' ; 判断对齐方向 '-' = 2D
jne align_righ
jmp align_left
align_righ:
call pad_char ; 填充空格
push [bp-102] ; 缓冲区长度地址
call append_char_to_buffer ; 字符追加写入缓冲区
jmp do_show_char_end
align_left:
push [bp-102] ; 缓冲区长度地址
call append_char_to_buffer ; 字符追加写入缓冲区
call pad_char ; 填充空格
do_show_char_end:
mov word ptr [bp-123],0 ; 宽度清零
add [bp-6],2 ; 指向下一个待处理参数
pop dx
pop cx
pop bx
ret
do_show_char endp
; ======================= 打印格式为字符 =======================
; ======================= 打印格式为整数 =======================
do_show_digit proc
pop dx
push bx
xor bx,bx
; 当前 di 已指向结果字符串地址
; 调用子程序 dtoc 将 word 转 10 进制数字
mov bl,[bp-128] ; -左对齐,否则右对齐
push bx
mov bl,[bp-127] ; 符号规则
push bx
mov bl,[bp-123] ; 宽度
push bx
mov bl,[bp-125] ; 填充字符
push bx
mov bx,[bp-6] ; 16位有符号整数(先取地址)
push [bx] ; 再取值
call dtoc
push [bp-102] ; 缓冲区长度地址
call print_buffer ; 清空缓冲区
mov word ptr [bp-123],0 ; 宽度清零
add [bp-6],2 ; 指向下一个待处理参数
pop bx
push dx
ret
do_show_digit endp
; ======================= 打印格式为整数 =======================
; ======================== 字符串转整数 ========================
; 将字符串形式的数字解析为数值
; 从左向右逐个读取字符,只要是数字就处理,最终返回对应的数值
; --------------------------------------------------------------
; 参数:ds:si 指向要解析的目标字符串
; 返回:ax 返回数值
; --------------------------------------------------------------
_parse_int proc
cbw
_parse_int_start:
sub al,'0' ; ascii 数字转数值
; 每向后取到一个数字,之前的累加结果就要进位(x10)再和本次的相加
xchg [bp-0123],ax ; 当前值与累加值互换
; 累加值 = 累加值 x 10 (位运算模拟x10:拆分成 x2 + x8)
shl ax,1
mov dx,ax
shl ax,1
shl ax,1
add ax,dx
; 累加值 = 累加值 + 当前值
add [bp-0123],ax
; 累加完成再读下一个
lodsb
; 如果不是数字就结束,否则继续
cmp al,'0'
jb _parse_int_end
cmp al,'9'
jg _parse_int_end
jmp _parse_int_start
_parse_int_end:
dec si ; 当前不是数字退出的,si 后退一位一遍上层逻辑继续
mov ax,[bp-0123] ; 返回 %所标示的打印宽度
ret
_parse_int endp
; ======================== 字符串转整数 ========================
; ======================== 整数转字符串 ========================
; 整数转字符串,以 0 结尾
; 1. 先判断要处理的整数正负,并做好标记(负数要转为原码,才能下一步)
; 2. 用除10取余的方式将整数转为字节
; 2.1. 因为这样得到的结果是倒序的比如 12345 得到结果的顺序是 54321
; 所以我们将每次得到的余数转字符压栈,后续再出栈到结果字符位置就行了。
; 3. 计算填充长度
; 3.1. 如果字符串长度 > 指定结果字符串长度,不用填充,否则进行填充
; 4. 填充
; 4.1. 根据符号规则与对齐方式有4种填充方式,分别是:
; 【无填充、左对齐填充、右对齐填充空格、右对齐填充0】
; 5. 最后统计一下字符串长度,存到 ax 中作为返回值
; --------------------------------------------------------------
; 参数:[bp+4] 16位有符号整数
; 参数:[bp+6] 填充字符
; 参数:[bp+8] 指定结果字符串长度
; 参数:[bp+10] 符号规则【 + 】:始终显示+-号
; 【空格】:正数显示空格,负数显示-
; 参数:[bp+12] 左对齐 【 - 】:左对齐,否则右对齐
; 参数:ds:[di] 结果字符串地址
; --------------------------------------------------------------
; 返回: ax 字符串长度
; --------------------------------------------------------------
dtoc proc
push bp
mov bp,sp
sub sp,16
push bx
push cx
push dx
push es
push si
mov [bp-2],di ; 保存字符串开始位置
jmp dtoc_start ; 跳到主逻辑代码开始位置
; ----- 处理符号 -----
sign_start:
cmp byte ptr [bp-3],'-' ; 判断当前数的正负(之前算过标记在这的)
je negative_number
positive_number:
dtoc_always_signs:
cmp word ptr [bp+10],'+' ; 始终显示+-号
jne dtoc_only_negative
mov byte ptr [di],'+'
jmp sign_end
dtoc_only_negative:
cmp byte ptr [bp+10],' ' ; 正数显示空格,负数显示-
jne sign_ret ; 不是 + 也不是空格则是默认规则:正数不显示,跳返回
mov byte ptr [di],' ' ; 否则正数显示空格
jmp sign_end
negative_number:
mov byte ptr [di],'-' ; 加上负号
sign_end:
inc di ; 符号占一位,di 后移
sign_ret:
ret
; ----- 填充 -----
pad_start:
xchg [bp+8],cx
mov ax,[bp+6] ; 取填充字符(只用 al)
cld ; 设置 DF = 0,,串操作时方向 ++
push ds
pop es
rep stosb ; 重复 cx 次,ds:[di] = al 然后 di++
xchg [bp+8],cx ; 取回结果字符长度
ret
; ----- 取出字符 -----
; 目前栈里是 54321 顺序不是我们想要的,遍历一下出栈到 ds:[di]... 就正了
pop_char:
pop dx
pop_char_s:
pop ax
mov [di],al ; 写入目标内存地址。第 di 个字符(我们只取低8位有效值)
inc di
loop pop_char_s
push dx
ret
; --------------------------------------------------------------
dtoc_start:
; ----- 判断正负 -----
mov byte ptr [bp-3],'+' ; 先假设是正数,标记符号为 +
mov ax,[bp+4]
mov bx,ax
and bx,1000000000000000b
cmp bx,1000000000000000b ; 符号位==1是负数
jne convert ; 如果是正数直接返回
dec ax ; 补码转反码
not ax ; 反码转原码
mov byte ptr [bp-3],'-' ; 标记符号为 -
; ----- 执行转换 -----
convert:
; 数字转字符(用除10取余实现)
xor cx,cx ; 循环变量从 0 开始
; 用遍历取余的方式拿到 ascii 拿到的结果是倒的
; 比如 12345 遍历取余拿到的是 54321 所以先丢栈里,方便下一步翻转
mov bx,10
dtoc_s: xor dx,dx ; 除数 bx 是 16 位,则被除数是32位。高16位 dx 没有数据要补 0
div bx ; 除完后 商在ax下次继续用,dx为余数
add dx,30H ; 将余数转 ascii
push dx ; 入栈备用(此时高8位是无意义的,之后我们只要取低8位用即可 )
inc cx ; 循环变量 +1
cmp ax,0 ; 如果商为0跳出循环
je dtoc_s_ok
jmp dtoc_s ; 否则继续循环
dtoc_s_ok:
; ----- 填充长度 -----
; 计算
count_len:
cmp word ptr [bp+8],0 ; 如果指定宽度 <=0 设为 0
jge count_pad_len
mov word ptr [bp+8],0
count_pad_len:
cmp [bp+8],cx
jbe no_pad ; 指定长度 < 字符串长度 :直接跳过,不用填充
sub [bp+8],cx ; 指定长度 - 字符串长度 = 填充个数
; 如果符号为正,且符号显示规则为 0,则直接开始填充,否则填充长度 -1
cmp byte ptr [bp-3],'+'
jne pan_len_dec
cmp byte ptr [bp+10],0
je alr
pan_len_dec:
dec word ptr [bp+8] ; 宽度 -1
; 填充开始
alr:
cmp byte ptr [bp+12],'-' ; 如果是右对齐
jne aright
aleft: ; 左对齐逻辑
call sign_start
call pop_char
mov byte ptr [bp+6],' ' ; 左对齐只能在右侧填充空格,填0值就不对了
call pad_start
jmp ret_l
aright: ; 右对齐逻辑
cmp byte ptr [bp+6],'0' ; 填充0:填在符号与数字之间 【+00012345】
je pad0
mov byte ptr [bp+6],' ' ; 填充空格:填在符号之前 【 +12345】
call pad_start
call sign_start
call pop_char
jmp ret_l
pad0:
call sign_start
call pad_start
call pop_char
jmp ret_l
no_pad: ; 无需填充
call sign_start
call pop_char
; ----- 返回 -----
ret_l:
mov ax,di ; 取字符串最后一个位置
sub ax,[bp-2] ; 尾 - 头 = 长度
mov byte ptr [di],0 ; 字符串以 0 结束
pop si
pop es
pop dx
pop cx
pop bx
add sp,16 ; 释放局部空间
mov sp,bp
pop bp
ret 10
dtoc endp
; ======================== 整数转字符串 ========================
_TEXT ends
end
- printc.c
extern void myprintf(const char *format, ...);
int main() {
myprintf("hello world %d %c", 6, 'a');
}
- printa.asm
DATA SEGMENT
db 512 dup(0) ; 定义数据
DATA ENDS
CODE SEGMENT
ASSUME CS:CODE, DS:DATA
; 函数开始
_myprintf PROC
push bp ; cs:30
mov bp,sp
sub sp,128 ; 开辟 128 的局部空间
mov bx,[bp+2] ; 取参数1地址
push ss
pop ds
mov ah,09 ; 显示 ds:dx 指向的字符串($结尾)
int 21h
ret
_myprintf ENDP
PUBLIC _myprintf ; 设为公共
CODE ENDS
END
main.c
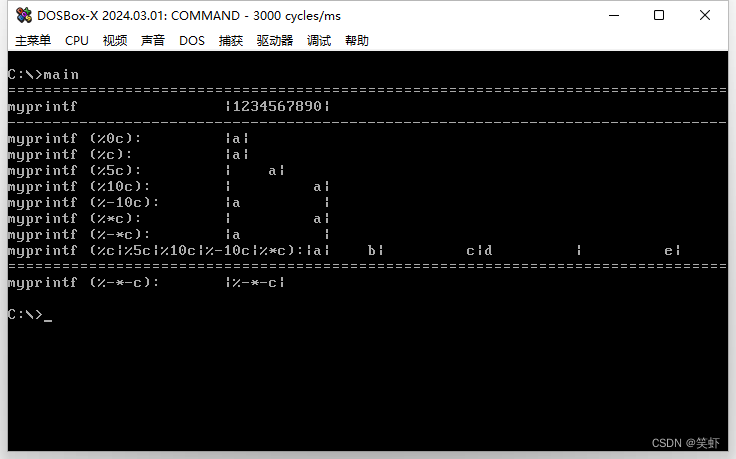
测试 %c
extern void myprintf(const char *format, ...);
void main() {
myprintf("================================================================================");
myprintf("myprintf |1234567890|\n\r");
myprintf("--------------------------------------------------------------------------------");
myprintf("myprintf (%%0c): |%0c|\n\r", 'a');
myprintf("myprintf (%%c): |%c|\n\r", 'a');
myprintf("myprintf (%%5c): |%5c|\n\r",'a');
myprintf("myprintf (%%10c): |%10c|\n\r", 'a');
myprintf("myprintf (%%-10c): |%-10c|\n\r", 'a');
myprintf("myprintf (%%*c): |%*c|\n\r", 10,'a');
myprintf("myprintf (%%-*c): |%-*c|\n\r", 10,'a');
myprintf("myprintf (%%c|%%5c|%%10c|%%-10c|%%*c):|%c|%5c|%10c|%-10c|%*c|\n\r", 'a', 'b', 'c', 'd', 10,'e');
myprintf("================================================================================");
myprintf("myprintf (%%-*-c): |%-*-c|\n\r", 10,'a');
return;
}
测试 %d 未指定宽度
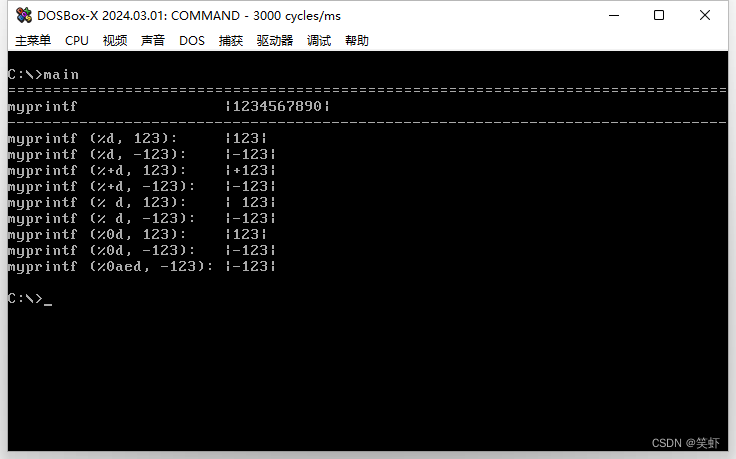
extern void myprintf(const char *format, ...);
void main() {
myprintf("================================================================================");
myprintf("myprintf |1234567890|\n\r");
myprintf("--------------------------------------------------------------------------------");
myprintf("myprintf (%%d, 123): |%d|\n\r", 123);
myprintf("myprintf (%%d, -123): |%d|\n\r", -123);
myprintf("myprintf (%%+d, 123): |%+d|\n\r", 123);
myprintf("myprintf (%%+d, -123): |%+d|\n\r", -123);
myprintf("myprintf (%% d, 123): |% d|\n\r", 123);
myprintf("myprintf (%% d, -123): |% d|\n\r", -123);
myprintf("myprintf (%%0d, 123): |%0d|\n\r", 123);
myprintf("myprintf (%%0d, -123): |%0d|\n\r", -123);
myprintf("myprintf (%%0aed, -123): |%0d|\n\r", -123);
return;
}
测试 %d 指定宽度
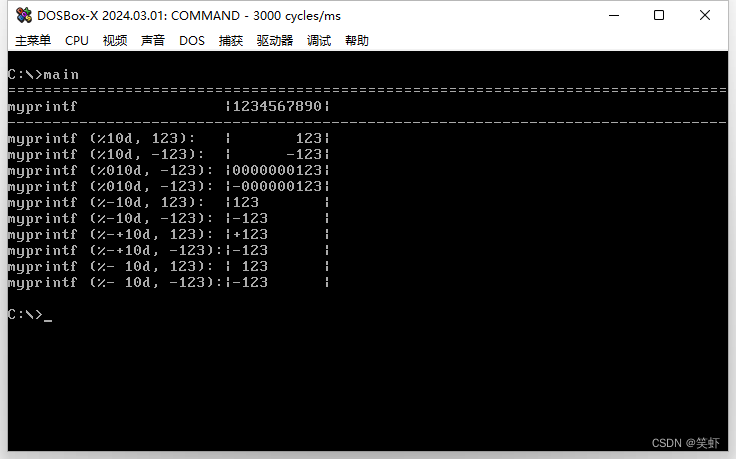
extern void myprintf(const char *format, ...);
void main() {
myprintf("================================================================================");
myprintf("myprintf |1234567890|\n\r");
myprintf("--------------------------------------------------------------------------------");
myprintf("myprintf (%%10d, 123): |%10d|\n\r", 123);
myprintf("myprintf (%%10d, -123): |%10d|\n\r", -123);
myprintf("myprintf (%%010d, -123): |%010d|\n\r", 123);
myprintf("myprintf (%%010d, -123): |%010d|\n\r", -123);
myprintf("myprintf (%%-10d, 123): |%-10d|\n\r", 123);
myprintf("myprintf (%%-10d, -123): |%-10d|\n\r", -123);
myprintf("myprintf (%%-+10d, 123): |%-+10d|\n\r", 123);
myprintf("myprintf (%%-+10d, -123):|%-+10d|\n\r", -123);
myprintf("myprintf (%%- 10d, 123): |%- 10d|\n\r", 123);
myprintf("myprintf (%%- 10d, -123):|%- 10d|\n\r", -123);
return;
}
测试 %d 单独用【参数】指定宽度
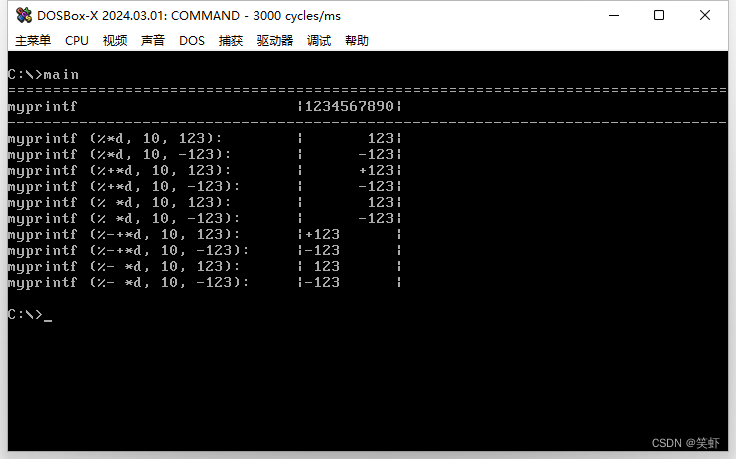
extern void myprintf(const char *format, ...);
void main() {
myprintf("================================================================================");
myprintf("myprintf |1234567890|\n\r");
myprintf("--------------------------------------------------------------------------------");
myprintf("myprintf (%%*d, 10, 123): |%*d|\n\r", 10, 123);
myprintf("myprintf (%%*d, 10, -123): |%*d|\n\r", 10, -123);
myprintf("myprintf (%%+*d, 10, 123): |%+*d|\n\r", 10, 123);
myprintf("myprintf (%%+*d, 10, -123): |%+*d|\n\r", 10, -123);
myprintf("myprintf (%% *d, 10, 123): |% *d|\n\r", 10, 123);
myprintf("myprintf (%% *d, 10, -123): |% *d|\n\r", 10, -123);
myprintf("myprintf (%%-+*d, 10, 123): |%-+*d|\n\r", 10, 123);
myprintf("myprintf (%%-+*d, 10, -123): |%-+*d|\n\r", 10, -123);
myprintf("myprintf (%%- *d, 10, 123): |%- *d|\n\r", 10, 123);
myprintf("myprintf (%%- *d, 10, -123): |%- *d|\n\r", 10, -123);
return;
}
总结
反汇编分析 C
- 反汇编分析时,可以先用
tcc -S demo.c拿到asm - 再用
masm demo.asm, demo.obj, demo.lst;拿到list辅助分析 - 偏移对不上可以手动在
asm加org指定一下
3.1. C语言中可以用printf("%x\n",main);打印main函数入口地址
参考资料
stormpeach:《关于tcc、tlink的编译链接机制的研究》
printf 反汇编分析过程,没全分析完。够回答就停了。留着可能有用: